

和伟大的北美高校不同,英国高校往往要求申请者在正式申请之前先和导师有联系,让导师帮助制定和修改研究计划,以争取每年为数不多的奖学金。如此一来,想找个书读的可怜人们就不得不花上大量时间逐个检索系内老师的页面,让原本就苦涩的博士申请过程变得更加繁重。
原本我也是手动逐个检索,但在不断扒拉学术主页的过程中,腱鞘炎感觉又要复发了,精神状况也变得不甚稳定,只好想想别的办法,写了个简单的爬虫来爬取页面数据,最后丢到 Claude 中去分析,先找到至少有一定匹配度的人选,再打开网页仔细搜寻。
然而,由于各个学校系科主页写法都不一样,有的更是堪称土豆服务器上长出的后现代垃圾,不停改爬虫脚本也不现实,再三尝试下,还是决定使用诸如可视化的爬虫服务,如八抓鱼、火车头或EasySpider,具体设置教学不再介绍,除了 EasySpider 我在各系统下都无法打开外,其他采集器都差不多简单。
具体流程上,在采集器中打开特定的教员名录页面,部分采集器会自动识别出要采集的内容(也就是教授的列表),如若没有找到就手动选一选(也不必会 CSS,点击筛选就好,这一点倒是很类似我爱用的 Arc Boost),随后要求采集二级页面,再进入教授的具体页面中进行查选。
教员名录与个人页面
考虑到大部分学校的网页组织结构类似,以上逻辑应该通用,唯一的问题是在教授学术页面内要采集什么内容,个人想法是如果愿意简单粗暴直接存整个 HTML,自然是可行,如若不行,也可以手动筛选一些例如个人简介、研究兴趣和最近发表等模块,采集结束之后导出成 CSV 或 JSON 都可以。
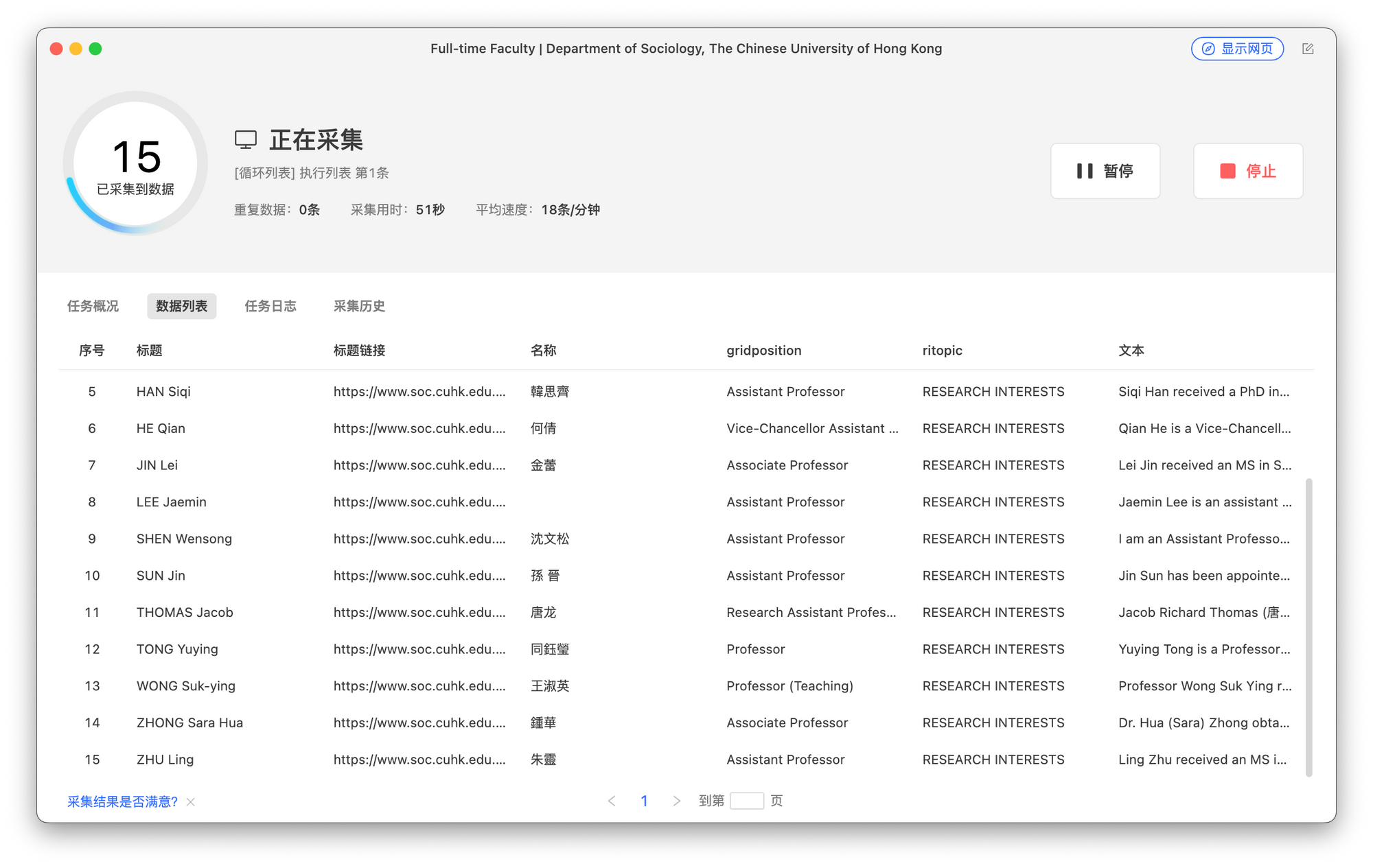
大概内容爬完了就是丢给 Claude 分析。如果你采集的内容不是很长,也许 ChatGPT 也可以,但保险起见还是交给上下文空间更长的 Claude 比较好。至于问题,既可以要求列出不同教授的兴趣,也可以问是否有教授和自己兴趣 ABCD 等交叉,甚至可以丢自己的论文上去问估计谁会喜欢这篇东西。

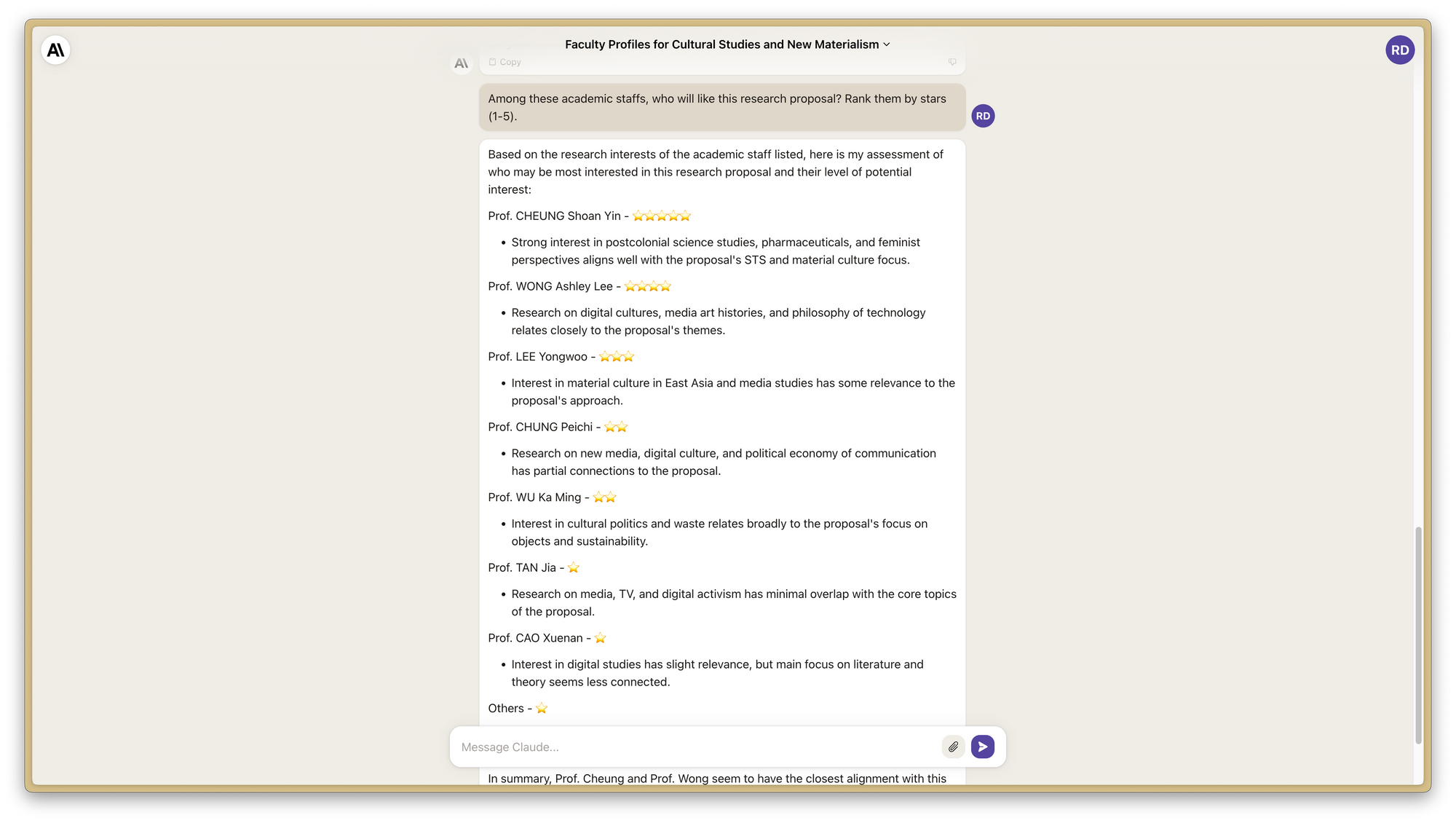
在确认了基本的兴趣后,大致就可以进入个人主页手动读阅了。至于是否有更高级的用法和更自动化的流程(例如直接让一个程序读 JSON,通过 Claude 的 API 来获得返回,或者是让 Claude 返回匹配程度),个人感觉没太多必要,通用性和实用性也不佳。
话说到这里,作为案例的港中文社会学系有没有和我兴趣匹配的导师呢?答案是没有。关掉页面的刹那,正可谓是一别两宽,相看两厌,若不是我恨社会学,就是社会学恨我。
