


在写《讲中文的机匹替》时为求速度,写得比较马虎,下午和小栋聊天时他提到几个数据和表达问题,我顺手测试了最新的 API 并进行修改。为便于阅读也贴在这里:
按多轮测试的结果,在英文中,一个「通证」就是大约是 4/3 个词;在中文中,一个「通证」则是一个字,这也符合中英文组成句子最小单位不同的特征。这种界定直接导致,OpenAI 的模型能够单次读取、持续记忆的中文信息量只有英文的 60% 左右,处理同样信息的文本消耗的费用也高了 40-60 %,与此同时响应速度也有相当相当程度的下降。
聊天时小栋提到怀疑 GPT 在处理德语时也会消耗大量通证(token),我想了下确实有可能,并且也是蛮有意思的问题,于是开始了两轮测试,基本测试方法如下:
- 使用机器翻译(DeepL)将文本翻译成其他几种语言;
- 用最新的 ChatGPT 将文本内容打过去;
- API 处理完毕后会返回请求的通证数,我们以此为准来记数。
两轮测试也特意制造了一些差别,例如一轮的语料是昨天在调试翻译咒语时使用的文段,相对专业,句子也比较复杂;另一轮时随手写的文段,都是简单句,不包括复杂逻辑,能尽量避免因归化词或翻译导致的问题。
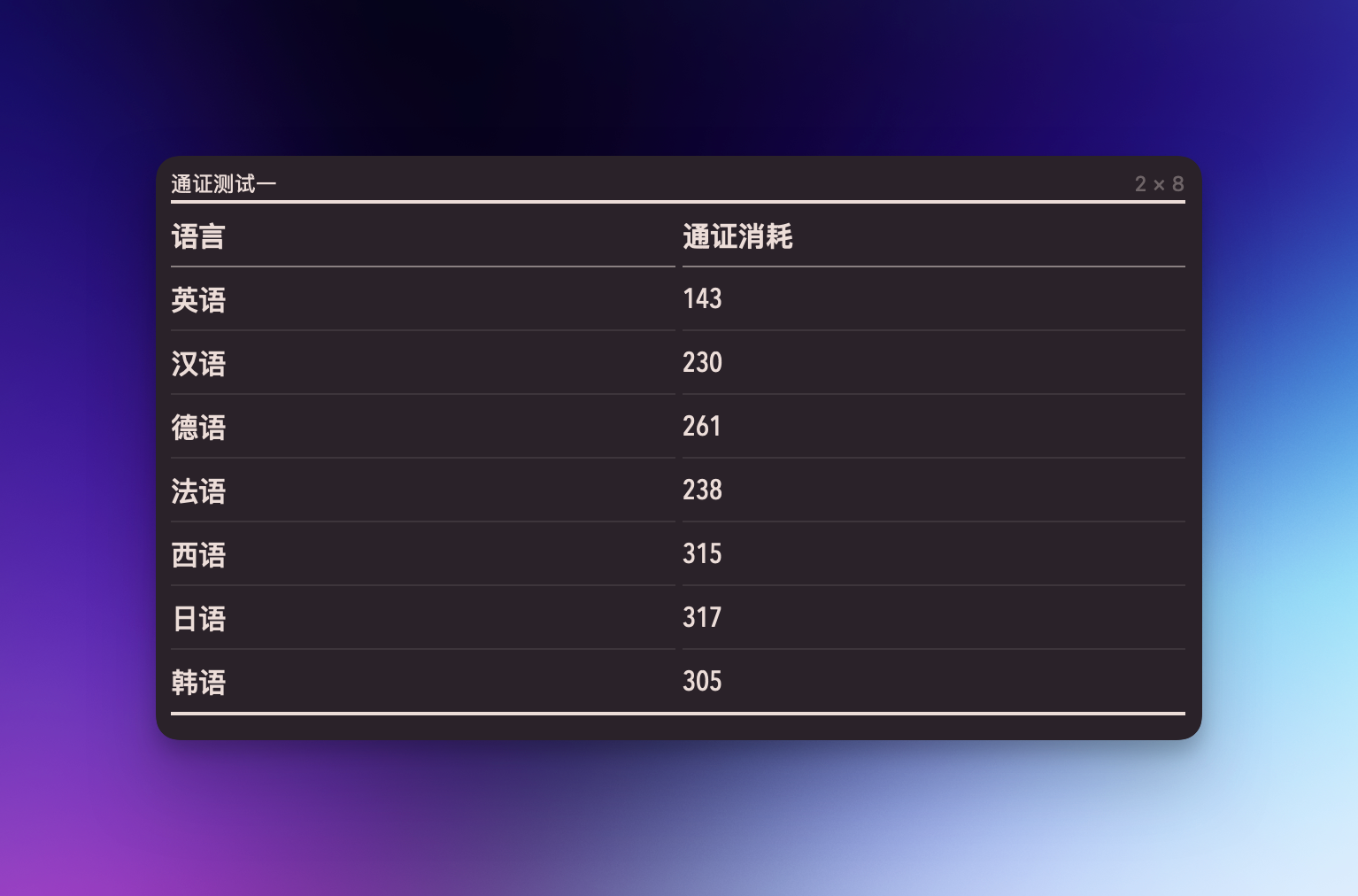
通证测试一
19世纪成功创造了一个复杂社会机制,以检查、分类和分析各种身体活动和解剖学问题。同时,它发明了一种弹性、流行的文学体裁,专注于调查身体,揭示和提交最肉体的秘密以供审查,并提供有关身体的残酷事实作为证据,以控制其功能,可能通过解释或禁固来实现。在这些叙事中,一种技术被设想出来,将可疑的身体呈现为可读的文本,而不是处罚的囚犯。这部文学作品的主人公——他引发的法医科学学科,以及体现在他身上的文化工具——是本书的研究对象。
通证测试二
我今天早上起来,吃了早餐。早餐是麦当劳,里面有两个汉堡和一份薯条。我用手机导航去地铁站,乘坐2号线,转乘8号线,最后到达公司。在公司我什么也没干。我一整天都在休息,在电脑前面吃薯片。下班后我回家休息。看了两部电影,希区柯克拍的电影我看不懂。我十点钟睡了,抱着毛绒熊玩具。

两轮测试结束后,小栋又提到闪米特语族可能问题更大,并找了个朋友要了一段阿语和中文的对应译文。我将这段译文的中文版本翻译成英文之后又进行了一轮对比,算是一个补充。
通证测试三
世界经济论坛每年都会发布一份「灯塔工厂」榜单,其中囊括了全球制造业智能化和数字化水平最高的企业。2021 年,联合利华位于江苏省苏州市的和路雪(Wall’s) 冰淇淋生产基地荣获全球灯塔工厂评级,成为国内智能制造的典范标杆。工厂每天生产 900 万支冰淇淋,并大规模采用数字化和智能技术。这有助于提高质量和效率,减少对环境的影响,并更好地满足消费者的需求。

时间测试
你需要解答一些数学题目,请依次回答。不回答计算过程。只回答答案。
1. 有一些鸡和兔子,它们共有88个头,244只脚,请问鸡和兔各有多少只?
2. 有甲乙丙三袋化肥,甲乙两袋共重32千克,乙丙两袋共重30千克,甲丙两袋共重22千克,求三袋化肥各重多少千克。
3. 果园里有杏树和桃树共248棵,桃树的棵数是杏树的3倍,求杏树、桃树各多少棵?
4. 100千克油菜籽可以榨油40千克,现在有油菜籽3700千克,可以榨油多少?
5. A和B在周长为400米的环形跑道上跑步,A每秒钟跑5米,B每秒钟跑3米,他们从同一地点同时出发,反向而跑,那么,二人从出发到第二次相遇需多长时间?
6. 5辆汽车4次可以运送100吨钢材,如果用同样的7辆汽车运送105吨钢材,需要运几次?
7. 果园里桃树的棵数是杏树的3倍,而且桃树比杏树多124棵。求杏树、桃树各多少棵?
8. 某小学300名师生共植树400棵,照这样计算,整个城市48000名师生共植树多少棵?
9. 一条河堤136米,每隔2米种植一棵树,一共要栽多少棵树?
10. 爸爸今年35岁,我今年5岁,今年爸爸的年龄是我的几倍?明年呢?

相比通证测试来说时间测试比较困难,因为测试过程中需要保证以下两点:
- 任务难度复杂度一致:对所有语言来说,这些任务的难度应当一致。例如你要求 GPT 在不同语言下答同样的面试题目,那么可能恰恰语料规模更大的语言有更多话可说,或者是思维更缜密,那么可能会因为「想更多」反而导致落后。同理,英语语料中的「涂尔干」信息更多,询问相关问题更可能得到比阿拉伯语更快的回答。此时不同语言语料的规模很可能对任务完成造成了影响,这种影响不源于「语言特性」,应当被排除。
- 任务具备一定复杂度:假定所有语言的任务在启动时都需要一段「启动时间」(API 响应过程中已经删掉了纯 HTTP 连接消耗的时间),那么只有具备一定复杂度的任务,才能通过较长的完成时间,将这段「启动时间」的影响剔除。在最好的情况下,任务的咒语还应该具备一些语言长度,也即不要过分强调运算,而是更侧重考核模型在不同语言下的语言理解能力。
根据以上要求,我能想到最佳测试对象是小学应用题。因此我拼凑了十道题目并对所有语言进行了五次测试,取其平均响应时间。由于网络延迟、题目翻译、测试次数等问题,数据不算非常严谨,但也能大致体现等级关系,有兴趣的人可以自己深化测试一下。
结果汇总
从小样本测试的结果来看,如果不考虑极端情况(例如小说、法国理论或德国哲学),对大部分人能接触的文本来说,如果以英语为基准,那么汉、德、法、西等语言的通证消耗倍率大约是 1.5 倍,日语和韩语是 2 倍,阿语则是 3 倍,速度则大致反之。对此有两个方向的解释:其一,对于英语和其他语言之间的差别,如我们此前所说,目前的 LLM 主要根据英文设计,尚未对其他系统进行优化,因此表现比较差;其二,对于非英文的语言之间的差别,不同语言的书面文字的表达效率原本就不一样。

此前我们讨论过第一个方向,现在则考虑第二个问题:特德姜多年前在《纽约客》上发表过一篇文章抱怨中文的文字系统过于复杂,认为它强调了历史延续,促进了国家统一,但是也阻碍了识字率的提升。特德姜幻想或许可以存在一种纯拼音的中文——二十世纪二十年代的知识分子确实思考过这个可能,大陆目前正在使用简化字也是这一运动的余韵——它将大大改变中文的面貌,让它更简单易读。
特德姜的文章掀起了诸多讨论,有人深以为然,也有人认为这只是数字时代的东方主义,人们毫无理由厌恶带有表意因素的书写文字,识字率和计算机的飞速发展也证明表意或表音并不绝对影响技术进步或理性思考。抛开这些争论,特德姜文章暗示了一种语言之间的高低关系,似乎有一些语言比另一些更具备效率——的确有许多研究得到类似的结论——而我们上述考虑的第二个问题也指向了同样的结果。然而一项数年前的研究采用不同的思路,得到了新的结果:
来自里昂大学、香港大学等高校的学者们,在研究了17种形态各异的语言后发现,即使语速差异巨大,各种语音的都具有相同的传输速率——每秒39比特。
这项研究考虑了信息密度和音节速率的关系,结果是两者成反比,说简单些:发音越快的语言,单个音节内包含的信息量就越少。我们引入这个研究并不是要讨论不同的语言之间的优劣,而只是要指出不同的语言存在形态的差异:假定不同语言表达音节的符号长度/密度相对接近,单音节信息密度更高的语言,就能以更少的书面空间(也就是上面我们测试的通证数),置换同等的信息;如果要引入不同类型语言和语系的表音符号差异,则很难找到标准化的方式进行估计,此处只能暂不讨论。
如果以上讨论显得有点复杂或是弯弯绕绕,那么我来做一个最简单的总结:不同的媒介、工具、技术具有不同的特性,而大型语言模型的特性之一或许就是更亲睐「单音节信息密度更高」的语言。正如今天的所有国家都能在计算机上打出自己的文字,技术的高速发展(尤其是成本的快速下降)终将内抹除此种差距,通过成本和性能的量级提升,使其不再成为问题。至于「终将」是如打字机那样的一个世纪,还是如许多技术乐天派所想的数年甚至数月,我们不得而知。唯一可以确定的是,眼下的非英语用户仍然只能以更高的代价,得到更差的响应。
在两年前的一次访谈中,特德姜说:「我倾向于认为大多数人对 A.I. 的恐惧。最好理解为对资本主义的恐惧。我认为大多数对技术的恐惧实际上也是如此。我们对技术的大部分恐惧或焦虑最好理解为对资本主义会如何利用技术来对付我们的恐惧或焦虑。技术和资本主义紧密地交织在一起,很难将两者区分开来。」对于我们来说,这则寓言还需要加上一个脚注:我们对技术的恐惧也是对西方的恐惧,我们害怕的是西方不经意地扩大和塑造东西方的「本质差距」,并将其伪装成技术发展的自然结果,抹杀不同的社会想象、技术路径和未来可能。
